Competition Data Observatory
Automated Data Observatory
Reprex
rOpenGov
Yes!Delft AI+Blockchain Validation Lab
Our Competition Data Observatory is a fully automated, open source, open data observatory that produces new indicators from open data sources and experimental big data sources, with authoritative copies and a modern API.
Our observatory is monitoring the certain segments of the European economy, and develops tools for computational antitrust in Europe. We take a critical SME-, intellectual property policy and competition policy point of view automation, robotization, and the AI revolution on the service-oriented European social market economy.
We would like to create early-warning, risk, economic effect, and impact indicators that can be used in scientific, business and policy contexts for professionals who are working on re-setting the European economy after a devastating pandemic and in the age of AI. We would like to map data between economic activities (NACE), antitrust markets, and sub-national, regional, metropolitian area data.
Get involved in services: our ongoing projects, team of contributors, open-source libraries and use our data for publications. See some use cases.
Follow news about us or the more comprehensive Data & Lyrics blog.
Contact us .
Download our competition presentation
Our Product/Market Fit was validated in the world’s 2nd ranked university-backed incubator program, the Yes!Delft AI Validation Lab.
Applications




Software
Accomplishments
Recent Posts










Contributors of the Digital Music Observatory
Join our open collaboration team as a data curator, developer or business developer! More about contributing: Automated Observatory Contributors’ Handbook.
developers
Andrés García Molina, PhD
Data Scientist
Botond Vitos
Data scientists and developer
Daniel Antal
Developer of open-source statistical software
Kasia Kulma
Contributor, data science and software engineering
Leo Lahti
rOpenGov coordinator
Pyry Kantanen
R package testing and data curation.
data curators
Borbála Dömötörfy
Competition data curator
Daniel Antal
Developer of open-source statistical software
Karel Volkaert
Economic policy data curator
Peter Ormosi
Competition and innovation data curator
Stephan Okhuijsen
Data visualization and dissemination
service development team
Annette Wong
Contributor, digital strategist and product marketer
Suzan Sidal
Business Case Development & Service Design
Robin Nagy
Mentor, Contributor, Business Development
institutional partners
rOpenGov
rOpenGov network
Datagraver
Data dissemination partner
join us
New Curators
Future curator
New Developers
Future co-developer
Observatory Business Associate
Future Team Member
Partners of the Green Deal Data Observatory
Join our open collaboration team as a data curator, developer or business developer! More about contributing: Automated Observatory Contributors’ Handbook.
developers
Andrés García Molina, PhD
Data Scientist
Botond Vitos
Data scientists and developer
Daniel Antal
Developer of open-source statistical software
Kasia Kulma
Contributor, data science and software engineering
Leo Lahti
rOpenGov coordinator
Pyry Kantanen
R package testing and data curation.
data curators
Borbála Dömötörfy
Competition data curator
Daniel Antal
Developer of open-source statistical software
Karel Volkaert
Economic policy data curator
Peter Ormosi
Competition and innovation data curator
Stephan Okhuijsen
Data visualization and dissemination
service development team
Annette Wong
Contributor, digital strategist and product marketer
Suzan Sidal
Business Case Development & Service Design
Robin Nagy
Mentor, Contributor, Business Development
institutional partners
rOpenGov
rOpenGov network
Datagraver
Data dissemination partner
join us
New Curators
Future curator
New Developers
Future co-developer
Observatory Business Associate
Future Team Member
Recent & Upcoming Talks




Featured Publications


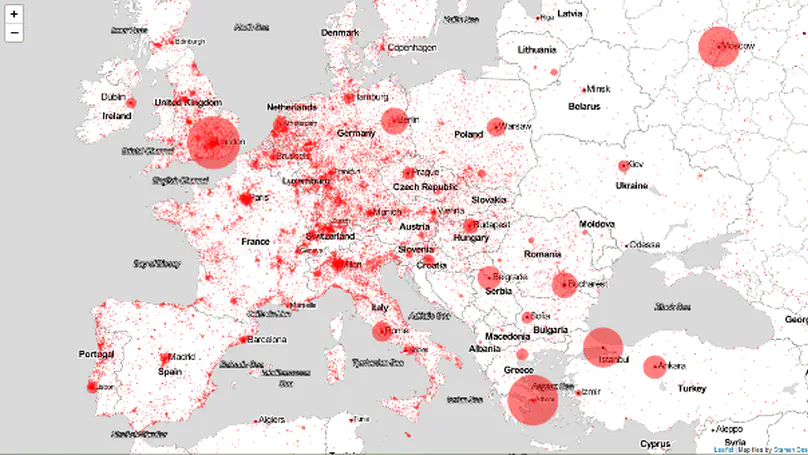


Recent Publications
Contact
- test@example.org
- 888 888 88 88
- 450 Serra Mall, Stanford, CA 94305
- Enter Building 1 and take the stairs to Office 200 on Floor 2
-
Monday 10:00 to 13:00
Wednesday 09:00 to 10:00 - Book an appointment
- DM Me
- Zoom Me